
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The CLIP network measures the similarity between natural text and images; in this work, we investigate the entanglement of the representation of word images and natural images in its image encoder. First, we find that the image encoder has an ability to match word images with natural images of scenes described by those words. This is consistent with previous research that suggests that the meaning and the spelling of a word might be entangled deep within the network. On the other hand, we also find that CLIP has a strong ability to match nonsense words, suggesting that processing of letters is separated from processing of their meaning. To explicitly determine whether the spelling capability of CLIP is separable, we devise a procedure for identifying representation subspaces that selectively isolate or eliminate spelling capabilities. We benchmark our methods against a range of retrieval tasks, and we also test them by measuring the appearance of text in CLIP-guided generated images. We find that our methods are able to cleanly separate spelling capabilities of CLIP from the visual processing of natural images. |
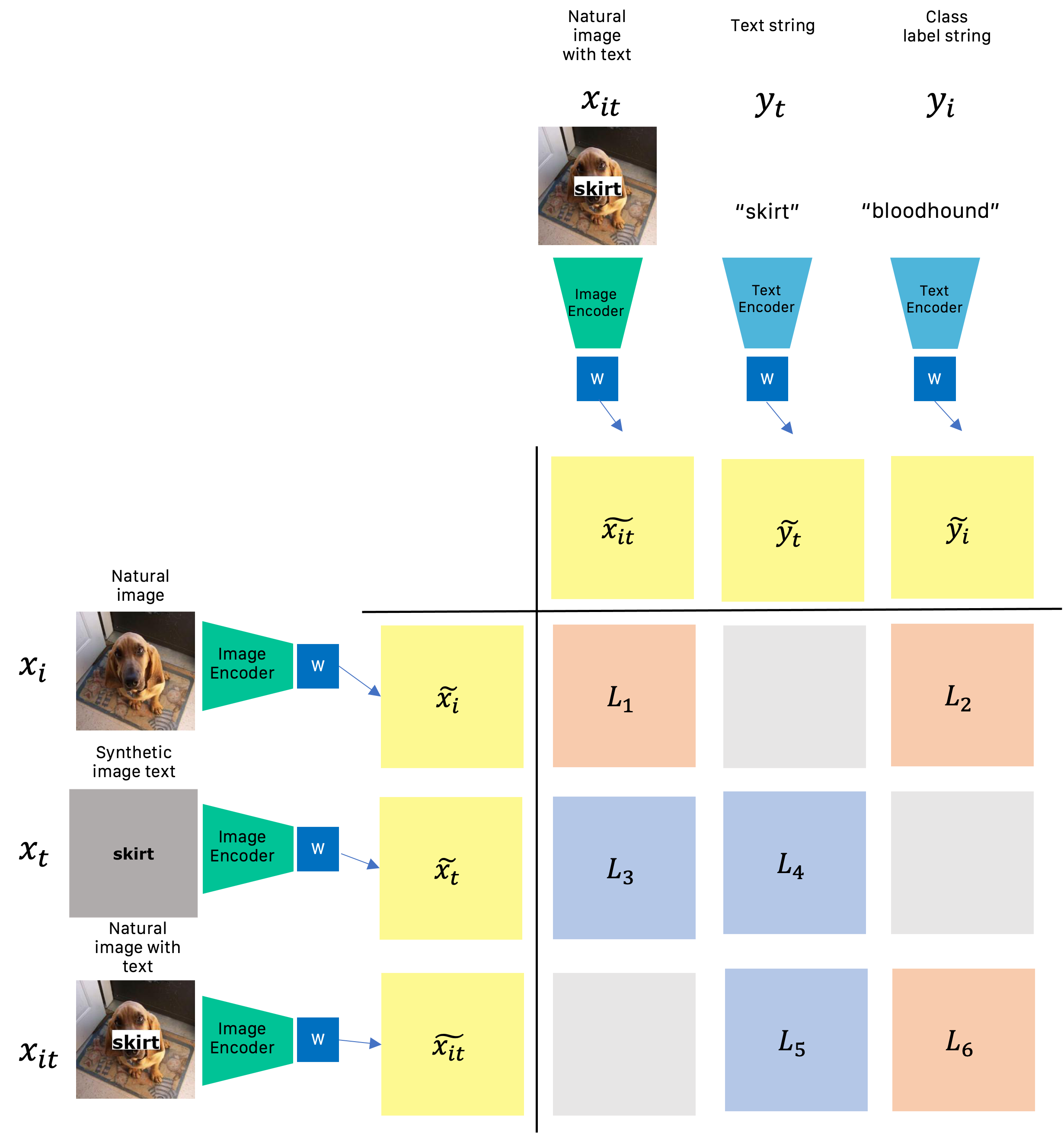
| We identify an orthogonal, lower-dimensional projection of the learned representations to disentangle the CLIP vector space’s visual space from the written one. To this end, we collect a dataset consisting of tuples with five elements natural images and their text class labels, image texts and text strings, and the natural image with the string from the synthetic image text rendered on it. Different pairs are trained to minimize their distance in the projection space. The losses in red correspond to the task of visual concepts, and the losses in blue to the distilling written words. We show the effectivness of the projection on various tasks from text-to-image generation to OCR. |
|
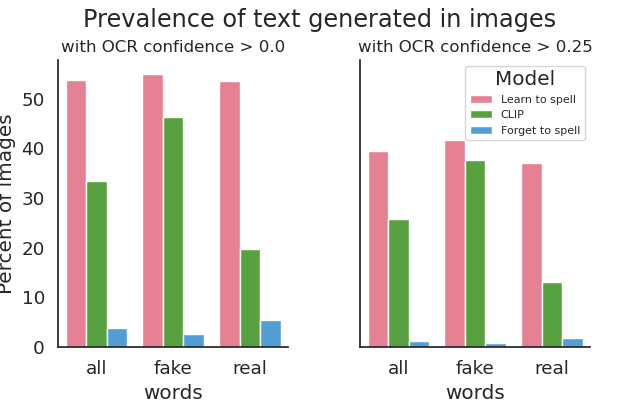
As a canvas for paining our learned projections, we use the VQGAN-CLIP framework to generate images besed on a text prompt. On one hand, we consider the CLIP network, the Learn to Spell model and the Forget to Spell model. |

|
| ||
We measure the appearance of text in images using an off the shelf OCR detector. |
|
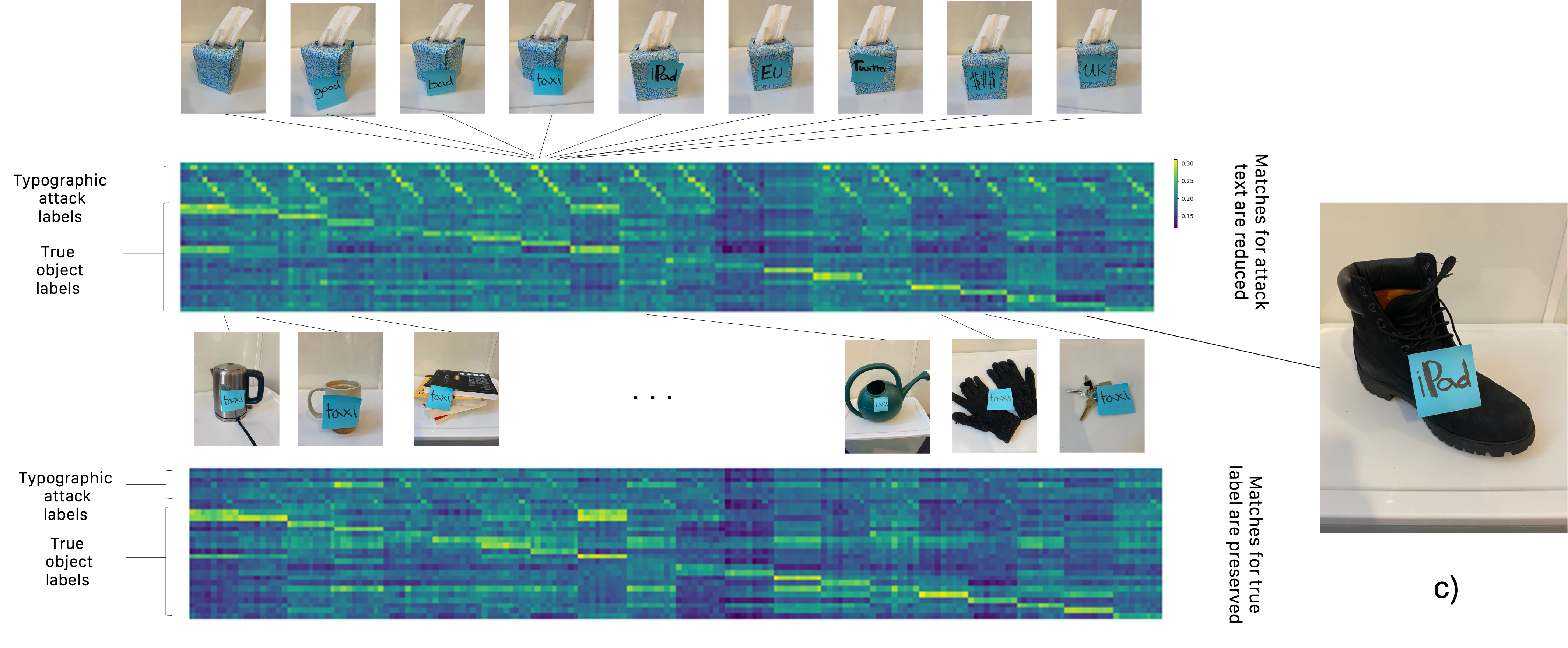
A test on a data set of 200 text attack images, a) shows a similarity matrix between the embeddings images with typographic attacks and the the text embeddings of typographic attack labels and true object labels obtained by the CLIP model, b) shows the same similarity matrix obtained by the Forget-to-Spell model. |
|
Acknowledgements |