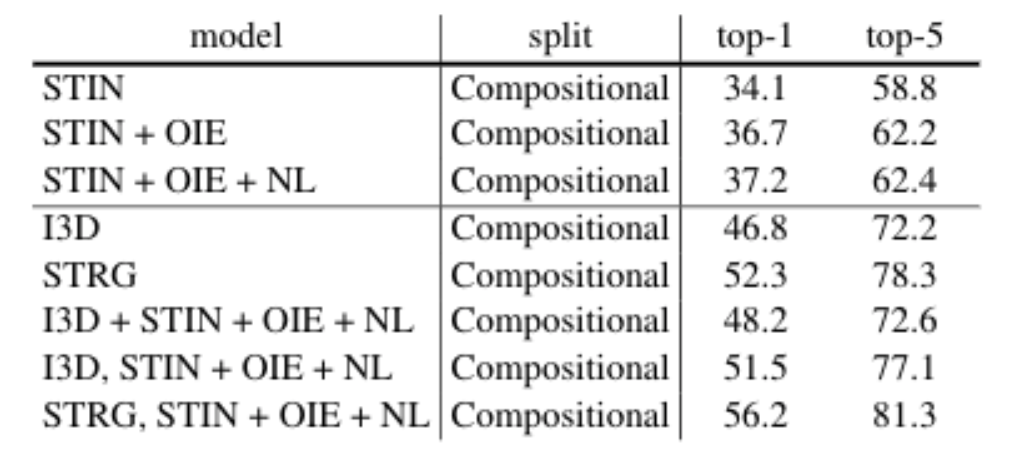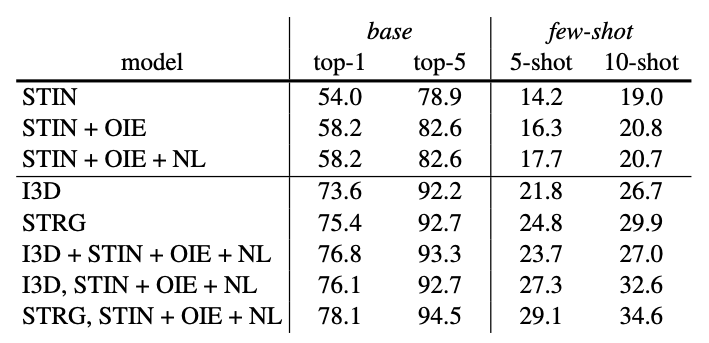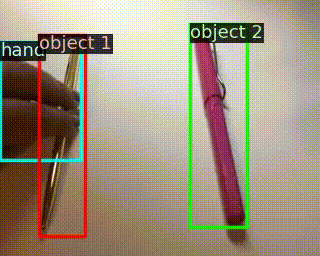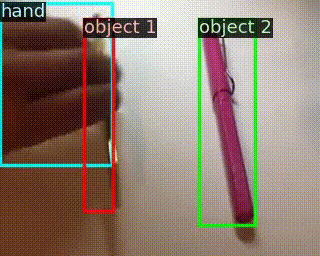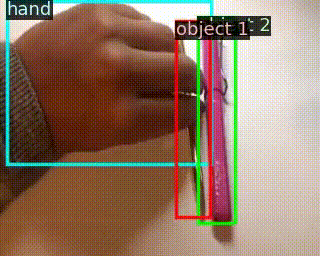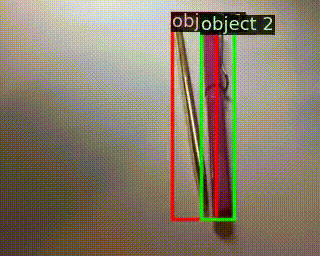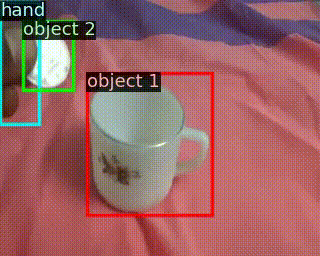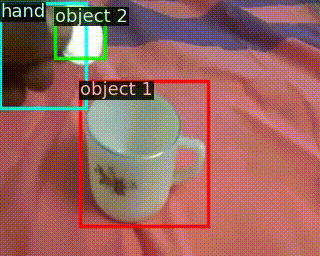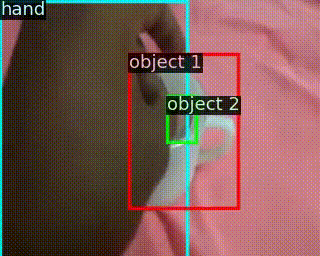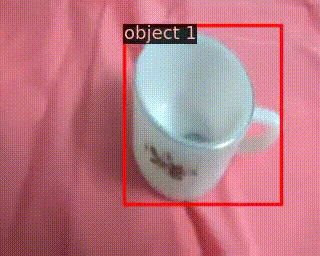
|
|
|
|
|
|
|
|
|
|
|
 |
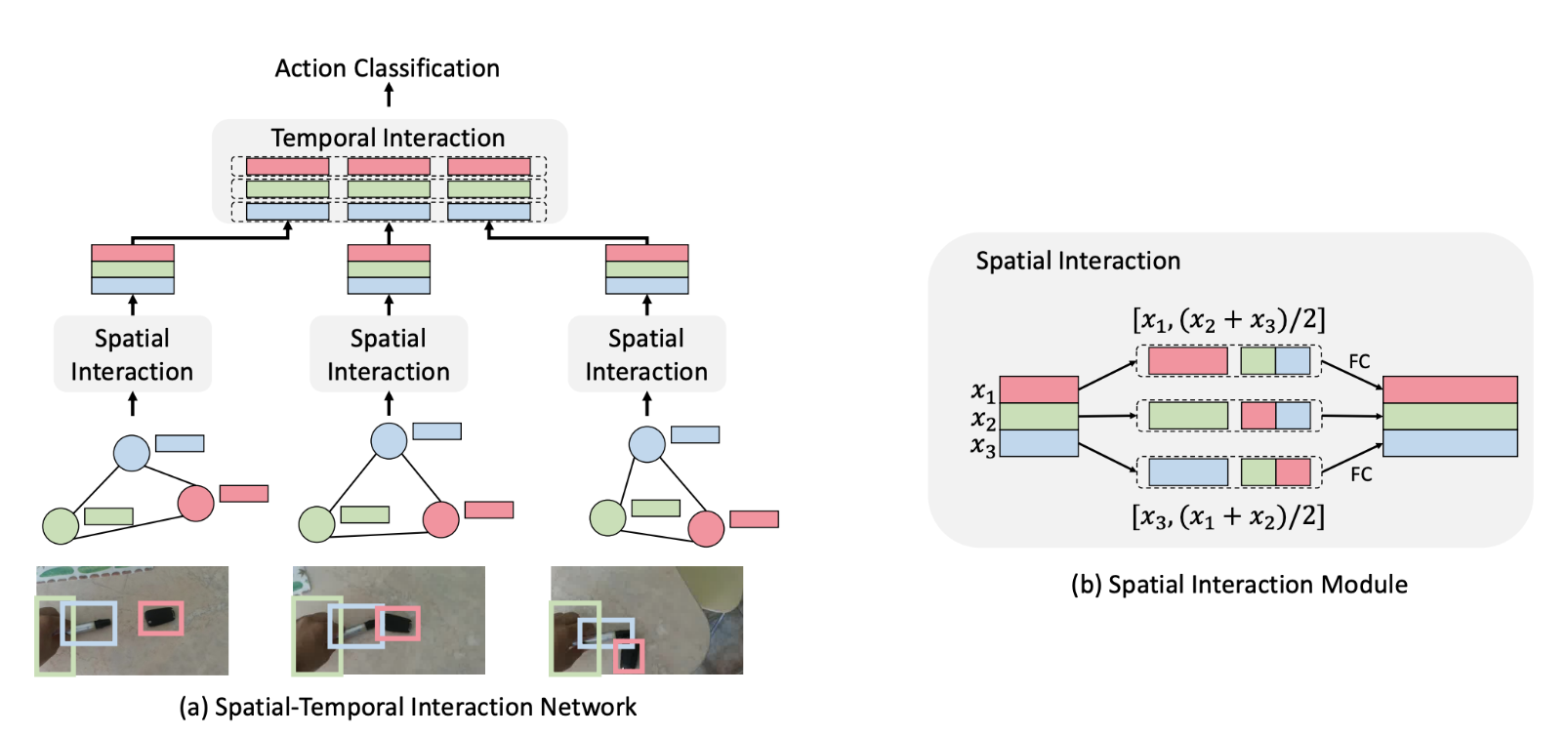
Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu*, Xiaolong Wang*, Trevor Darrell* Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks In CVPR, 2020. (hosted on arXiv) |
Acknowledgements |